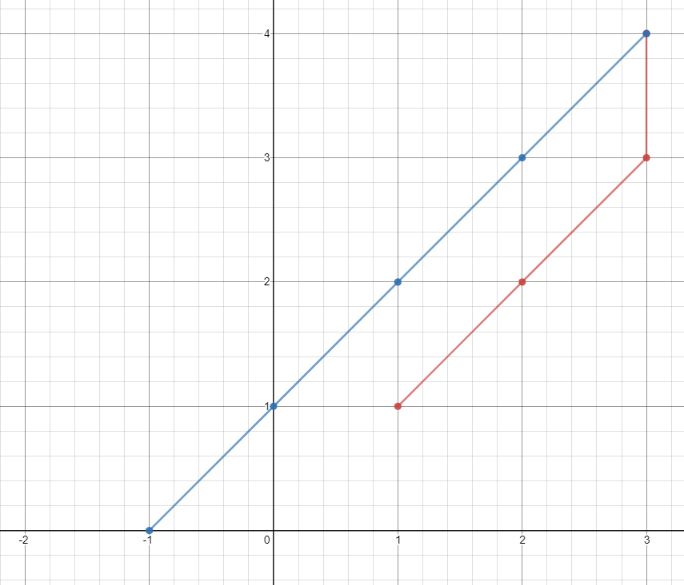
classSolution: defminTimeToVisitAllPoints(self, points: List[List[int]]) -> int: time = 0 for i in range(len(points)-1): time += max(abs(points[i+1][0] - points[i][0]),abs(points[i+1][1] - points[i][1])) return time
[Solved] 1267.统计参与通信的服务器
题目描述:
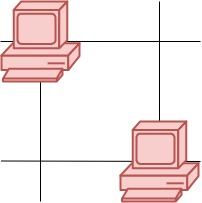
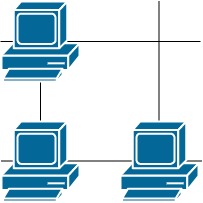
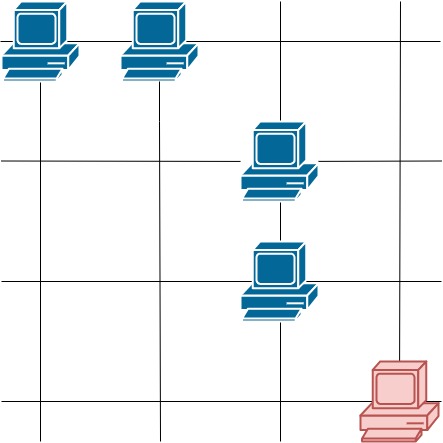
这里有一幅服务器分布图,服务器的位置标识在 m * n 的整数矩阵网格 grid 中,1 表示单元格上有服务器,0 表示没有。
for i in range(len(row)): for j in range(len(col)): if grid[i][j] == 1: row[i] += 1 col[j] += 1 duplicated = 0 sum_of_row = 0 for i, num in enumerate(row): if num >=2: sum_of_row += num for j, num_j in enumerate(col): if num_j >= 2and grid[i][j] == 1: duplicated += 1
sum_of_col = 0 for num_j in col: if num_j >= 2: sum_of_col += num_j result = sum_of_col + sum_of_row - duplicated
classSolution: defsuggestedProducts(self, products, searchWord): result = [[] for _ in range(len(searchWord))] products = sorted(products)
for i in range(1, len(searchWord)+1): for prod in products: if searchWord[:i] == prod[:i] and len(result[i-1]) < 3: result[i-1].append(prod) if len(result[i-1]) == 3: break
definsert(self, word): node = self.root for c in word: if c notin node.data: node.data[c] = TrieNode() node = node.data[c] node.is_word = True node.count += 1 defsearch(self, word): node = self.root for c in word: node = node.data.get(c) ifnot node: returnFalse return node.is_word
defstarts_with(self, prefix): node = self.root for c in prefix: node = node.data.get(c) ifnot node: returnFalse returnTrue
defget_start(self, prefix): def_get_key(pre, pre_node, words_list): if pre_node.is_word: for _ in range(pre_node.count): if len(words_list) == 3: return words_list.append(pre) for x in sorted(pre_node.data.keys()): if len(words_list) == 3: break _get_key(pre + x, pre_node.data[x], words_list) words = [] ifnot self.starts_with(prefix): return words
node = self.root for c in prefix: node = node.data[c]
_get_key(prefix, node, words)
return words
classSolution: defsuggestedProducts(self, products, searchWord): result = [] t = Trie()
for prod in products: t.insert(prod) for i in range(1, len(searchWord)+1): result.append(t.get_start(searchWord[:i]))
classSolution: defsuggestedProducts(self, products: List[str], searchWord: str) -> List[List[str]]: products.sort() ans=[[] for _ in range(len(searchWord))] cur=0 for i in range(len(searchWord)): k=3 for j in range(cur,len(products)): if products[j][:i+1]==searchWord[:i+1]: ans[i]+=[products[j]] k-=1 if k==0: cur=j-2 break if ans[i]==[]: return ans return ans
classSolution(): defnumWays(self, steps, arrLen): j_max = min(steps, arrLen) result_table = [[0] * min(j_max, steps-i+1) for i in range(steps+1)] result_table[0][0] = 1 MOD = 10**9 + 7 # Note: After optimizing the right-down space, maybe the several rows at the top have # the same length of the rows. When (steps-i+1) is smaller than j_max, # the len(dp[i]) = len(dp[i-1])-1 for i in range(1, steps+1): for j in range(len(result_table[i])): if j == 0: result_table[i][j] = (result_table[i-1][0] + result_table[i-1][1]) % MOD elif j == j_max -1: result_table[i][j] = (result_table[i-1][j-1] + result_table[i-1][j]) % MOD else: result_table[i][j] = (result_table[i-1][j-1] + result_table[i-1][j] + \ result_table[i-1][j+1]) % MOD return result_table[-1][0]